对 ChatGPT o1 的第一印象:一款被设计得过度思考的人工智能

OpenAI 于周四发布了其新的 o1 模型,这让 ChatGPT 用户首次有机会尝试在回答之前会暂停“思考”的人工智能模型。在 OpenAI 内部,这些代号为“草莓”的模型在发布前已经被大肆宣传。但“草莓”是否名副其实呢?
有几分;在一定程度上;可以这么说
与 GPT-4o 相比,o1 模型给人的感觉是前进了一步,又后退了两步。ChatGPT o1 擅长推理和回答复杂问题,但使用该模型的成本大约是 GPT-4o 的四倍。OpenAI 的最新模型缺乏使 GPT-4o 如此出色的工具、多模态能力和速度。事实上,OpenAI 甚至在其帮助页面上承认“对于大多数提示,GPT-4o 仍然是最佳选择”,并在其他地方指出 GPT o1 在较简单的任务上表现不佳。
纽约大学研究人工智能模型的教授拉维德·施瓦茨·齐夫(Ravid Shwartz Ziv)表示:“这令人印象深刻,但我认为改进不是非常显著。它在某些问题上表现更好,但并非全面提升。”
出于所有这些原因,重要的是仅将 GPT-01 用于其真正旨在帮助解决的问题:重大问题。需要明确的是,如今大多数人并未使用生成式人工智能来回答此类问题,主要是因为当今的人工智能模型在这方面还不是很擅长。然而,01 是朝着这个方向迈出的试探性一步。 (需要说明的是,您提供的内容中“GPT o1”和“o1”可能存在错误,也许您想说的是“GPT-1”或其他特定的名称或术语。)
深入思考重大理念
ChatGPT o1 的独特之处在于它在回答之前会“思考”,将大问题分解为小步骤,并尝试确定这些步骤的对错。这种“多步骤推理”并非全新的(研究人员多年来已提出过,而且 You.com 将其用于复杂查询),但直到最近才变得实用。
Workera 首席执行官兼斯坦福大学教授基安·卡坦福鲁什(Kian Katanforoosh)在一次采访中表示,他教授机器学习课程,“人工智能领域令人十分兴奋。如果你能训练一种强化学习算法,并将其与 OpenAI 的一些语言模型技术相结合,从技术上讲,你就可以创建逐步思考的能力,并让人工智能模型从你试图解决的重大想法逆向推导。”
ChatGPT o1 也特别昂贵。在大多数模型中,您为输入令牌和输出令牌付费。然而,ChatGPT o1 增加了一个隐藏的过程(模型将大问题分解成的小步骤),这增加了大量您从未完全看到的计算量。OpenAI 隐藏了此过程的一些细节以保持其竞争优势。也就是说,您仍然会以“推理令牌”的形式为此付费。这进一步强调了为什么您在使用 ChatGPT o1 时需要小心,以免因为询问内华达州的首府在哪里而被收取大量令牌费用。
不过,有一种人工智能模型能帮助你“从宏大的想法倒推”,这个想法很强大。实际上,该模型在这方面做得相当不错。
在一个例子中,我让 ChatGPT o1 预览版帮助我的家人规划感恩节,这个任务可能会受益于一些公正的逻辑和推理。具体来说,我想弄清楚两个烤箱是否足以为 11 人烹制感恩节晚餐,并想讨论一下我们是否应该考虑租一个爱彼迎民宿以使用第三个烤箱。
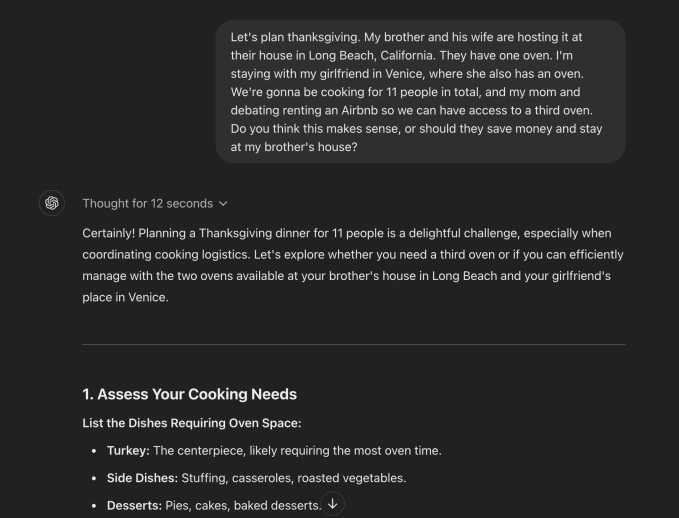
经过 12 秒的“思考”,ChatGPT 给我写了一篇 750 多个单词的回复,最终告诉我,如果精心规划,两个烤箱就足够了,这能让我的家人节省成本并且有更多时间相聚。但它在每一步都为我详细阐述了它的思考过程,并解释了它是如何考虑所有这些外部因素的,包括成本、家庭时间和烤箱管理。
ChatGPT 告诉我如何在举办活动的房子里优先安排烤箱空间,这很明智。奇怪的是,它建议我考虑当天租一个便携式烤箱。也就是说,这个模型的表现比 GPT-4 好得多,GPT-4 要求我多次后续说明我要带的确切菜肴,然后给我的建议很简略,我觉得用处不大。
询问有关感恩节晚餐的事宜可能看起来很傻,但你可以明白这个工具对于分解复杂任务会有多大帮助。
我还让 ChatGPT 帮我规划一个忙碌的工作日,在这一天里我需要往返于机场、在不同地点参加多个面对面会议以及去办公室。它给了我一个非常详细的计划,但可能有点太过了。有时候,所有额外增加的步骤会让人有点应接不暇。
对于一个简单的问题,ChatGPT o1 做得太过了——它不知道何时停止过度思考。我问在美国哪里能找到雪松树,它给出了 800 多个字的回答,概述了美国各种雪松树的情况,包括它们的学名。不知为何,它甚至在某个时候还得参考 OpenAI 的政策。GPT-4o 在回答这个问题时做得好多了,给了我大概三句话,解释说在全国各地都能找到这些树。
“Tempering expectations”常见释义为“降低期望;调整期望”
在某些方面,Strawberry 从未达到人们的过高期望。关于 OpenAI 推理模型的报道可追溯至 2023 年 11 月,当时所有人都在探寻 OpenAI 董事会驱逐山姆·奥特曼的原因。这在人工智能领域引发了谣言,使得一些人猜测 Strawberry 是一种通用人工智能(AGI),即 OpenAI 最终渴望创造的那种高级人工智能形式。
奥特曼证实 o1 不是通用人工智能以消除任何疑虑,倒不是说你用了这东西之后还会感到困惑。这位首席执行官还降低了对此次发布的预期,他在推特上写道:“o1 仍然存在缺陷,仍然有限,而且初用时似乎比你用久了之后更令人印象深刻。”
人工智能领域的其他方面正在接受这样一个事实:其发布不如预期那样令人兴奋。
“这种炒作在某种程度上超出了 OpenAI 的控制,”人工智能初创公司 ReWorkd 的研究工程师罗汉·潘迪(Rohan Pandey)说,该公司使用 OpenAI 的模型构建网络爬虫。
他希望 o1 的推理能力足够出色,能够解决 GPT-4 无法解决的一系列小众复杂问题。这可能是业内大多数人对 ChatGPT o1 的看法,但它并不像 GPT-4 对该行业那样是具有革命性的进步步骤。
Brightwave 首席执行官迈克·康诺弗(Mike Conover)在接受采访时表示:“每个人都在等待能力的阶跃函数式变化,但不清楚这是否代表了这种变化。我认为就是这么简单。”迈克·康诺弗此前曾参与创建 Databricks 的人工智能模型多莉(Dolly)。
这里的价值是什么?
创建 O1 所使用的基本原理可以追溯到多年前。风险投资公司 S32 的前谷歌员工兼首席执行官安迪·哈里森(Andy Harrison)指出,谷歌在 2016 年使用了类似的技术来创建 AlphaGo,这是第一个在围棋比赛中击败世界冠军的人工智能系统。AlphaGo 通过无数次与自己对弈进行训练,本质上是自我学习,直到达到超人的能力。
他指出,这引发了人工智能领域一个由来已久的争论。
哈里森在一次采访中说:“阵营一认为,你可以通过这种代理流程实现工作流程的自动化。阵营二认为,如果你拥有通用的智能和推理能力,就不需要工作流程了,而且像人类一样,人工智能会直接做出判断。”
哈里森表示,他属于阵营一,而阵营二则要求你信任人工智能能够做出正确的决策。他认为我们还没达到那个程度。
然而,另一些人认为 o1 不太像是一个决策者,而更像是一个在重大决策上质疑你思维的工具。
Workera 的首席执行官 Katanforoosh 描述了一个例子,他准备面试一位数据科学家来他的公司工作。他告诉 ChatGPT o1 他只有 30 分钟,并且想要评估一定数量的技能。他可以与这个人工智能模型反向推导,以了解自己的想法是否正确,ChatGPT o1 会理解时间限制之类的因素。
问题在于这个有用的工具是否值这么高的价格。随着人工智能模型的价格持续降低,o1 是我们长久以来见到的首批价格上涨的人工智能模型之一。
推荐阅读
TechCrunch 一分钟:Meta 承认正在抓取所有公开帖子用于人工智能训练

Meta 重新启动使用英国用户在 Facebook 和 Instagram 上的公开帖子来训练人工智能的计划。
万塔公司的克里斯蒂娜·卡西奥波在 2024 年的 TechCrunch Disrupt 大会上登台。

好呀,请您为我提供需要翻译成简体中文的英文内容吧,这样我才能为您进行翻译。

在 2024 年 TechCrunch Disrupt 大会上与安德森·霍洛维茨基金合伙人马丁·卡萨多的炉边谈话
