Meta 的 Llama AI 模型具备多模态能力

本杰明·富兰克林曾写道,除了死亡和税收,没有什么是确定无疑的。让我修改一下这句话,以反映当前的人工智能热潮:除了死亡、税收和新的人工智能模型,没有什么是确定无疑的,而这三者中的最后一项正以不断加快的速度涌现。
本周早些时候,谷歌发布了升级后的 Gemini 模型,本月早些时候,OpenAI 推出了其 o1 模型。但在周三,轮到 Meta 在其位于门洛帕克举行的年度 Meta Connect 2024 开发者大会上展示其最新成果了。
“羊驼(Llama)的多模态”
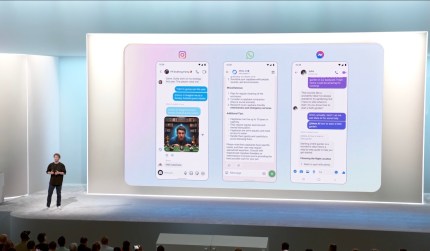
Meta 的多语言 Llama 模型系列已更新至 3.2 版本,从 3.1 版本的升级意味着几个 Llama 模型现在是多模态的。Llama 3.2 中的 11B (一个小型模型)和 90B(一个更大、功能更强的模型)能够根据简单描述解读图表、为图像添加标题,并识别图片中的物体。
例如,给定一张公园地图,Llama 3.2 11B 和 90B 可能能够回答诸如“地形何时会变得更陡峭?”和“这条路径的距离是多少?”之类的问题。或者,提供一张显示公司一年中收入的图表,这些模型可以迅速指出其中表现最佳的月份。
对于那些希望将模型严格用于文本应用的开发者,Meta 表示,Llama 3.2 11B 和 90B 被设计为 3.1 版本中 11B 的“即插即用”替代品。并且 90B 可以在有或没有新的安全工具 Llama Guard Vision 的情况下进行部署,该工具旨在检测输入模型或由模型生成的可能有害(即有偏见或有毒)的文本和图像。
在世界上的大部分地区,多模态的 Llama 模型可以从众多云平台下载和使用,包括 Hugging Face、微软 Azure、谷歌云以及 AWS。Meta 还将它们托管在官方的 Llama 网站 Llama.com 上,并利用它们为其人工智能助手 Meta AI 提供支持,应用于 WhatsApp、Instagram 和 Facebook 等平台。
但 Llama 3.2 11B 和 90B 在欧洲无法访问。因此,Meta AI 在其他地区可用的一些功能,如图像分析,对欧洲用户是禁用的。Meta 再次指责欧盟监管环境的“不可预测”性质。
Meta 对《人工智能法案》(AI Act)表示担忧,并拒绝了与之相关的自愿安全承诺。该欧盟法律为人工智能建立了法律和监管框架。除其他要求外,《人工智能法案》规定,在欧盟开发人工智能的公司必须确定其模型是否可能被用于“高风险”情况,如警务工作。Meta 担心其模型的“开放性”(这使其几乎无法了解模型的使用方式)可能会使其难以遵守《人工智能法案》的规定。
对于 Meta 来说,同样存在问题的还有欧盟广泛的隐私法《通用数据保护条例》(GDPR)中与人工智能训练相关的条款。Meta 基于未选择退出的 Instagram 和 Facebook 用户的公开数据来训练模型——在欧洲,这些数据受到 GDPR 保障条款的约束。今年早些时候,欧盟监管机构要求 Meta 在他们评估该公司是否符合 GDPR 规定期间,停止基于欧洲用户数据进行训练。
Meta 做出了让步,同时支持一封公开信,呼吁对《通用数据保护条例》进行“现代解读”,不要“拒绝进步”。
本月早些时候,Meta 表示,在将“监管反馈意见纳入”修订后的退出流程后,将恢复对英国用户数据的训练。但该公司尚未分享其在整个欧盟其他地区的训练情况的最新信息。
“More compact models”常见释义为“更紧凑的模型”
其他新的羊驼模型——那些未基于欧洲用户数据进行训练的模型——将于周三在欧洲(及全球)推出。
Llama 3.2 1B 和 3B 是两个轻量级的纯文本模型,专为在智能手机和其他边缘设备上运行而设计,可应用于总结和改写段落(例如在电子邮件中)等任务。Meta 表示,1B 和 3B 针对高通和联发科的 Arm 硬件进行了优化,经过一些配置,还能够使用诸如日历应用程序之类的工具,从而能够自主采取行动。
8 月份发布的旗舰版 Llama 3.1 405B 模型目前没有后续的多模态版本,无论是有还是没有。鉴于 405B 的规模巨大——训练耗时数月——这很可能是计算资源受限的问题。我们已经询问了 Meta 是否还有其他因素在起作用,如果得到回复,我们将更新此报道。
Meta 的新 Llama Stack,一套以 Llama 为重点的开发工具,可以用于对所有 Llama 3.2 模型(1B、3B、11B 和 90B)进行微调。Meta 称,无论如何定制,这些模型一次最多可以处理约 10 万个单词。
一场争夺心智份额的较量
Meta 首席执行官马克·扎克伯格经常谈到要确保所有人都能获得人工智能的“益处和机会”。然而,这种言辞背后隐含着一种愿望,即这些工具和模型由 Meta 打造。
在能够实现商品化的模型上投入资金,这会迫使竞争对手(例如 OpenAI、Anthropic)降低价格,广泛传播 Meta 的人工智能版本,并让 Meta 吸收来自开源社区的改进成果。Meta 声称其 Llama 模型的下载量已超过 3.5 亿次,并且被包括 Zoom、AT&T 和高盛在内的大型企业所使用。
对于许多这些开发者和公司来说,Llama 模型在最严格的意义上并非“开放”这一点无关紧要。Meta 的许可证限制了某些开发者对其的使用方式;每月用户超过 7 亿的平台必须向 Meta 请求特殊许可证,而该公司将自行决定是否授予。
诚然,很少有这种规模的平台没有自己的内部模型。但 Meta 在这个过程中并不是特别透明。本月当我询问该公司是否已经为某个平台批准了 Llama 的自主授权时,一位发言人告诉我,Meta“在这个话题上没有任何可分享的内容”。
毫无疑问,Meta 是志在必得。它花费数百万美元游说监管机构,以使其接受自己所倾向的“开放”人工智能模式,同时还投入数十亿资金用于服务器、数据中心和网络基础设施,以训练未来的模型。
Llama 3.2 模型没有一个能解决当今人工智能存在的首要问题,比如它编造内容和重复有问题的训练数据的倾向(例如可能未经授权就被使用的有版权的电子书,这是针对 Meta 的集体诉讼的主题)。但是,正如我之前所写的,它们确实推进了 Meta 的一个关键目标:成为人工智能的代名词,尤其是生成式人工智能的代名词。