本周AI:别忘了谦卑的数据标注员

要紧跟快速发展的人工智能行业,这是个艰巨的任务。所以在人工智能可以为你做到之前,这里有一些方便的汇总,涵盖了机器学习世界最近的故事,以及我们没有单独报道的值得关注的研究和实验。
本周在AI领域,我想把焦点放在标注和注释初创公司上 - 像Scale AI这样的初创公司,据报道正在洽谈以130亿美元的估值筹集新资金。标注和注释平台可能不像OpenAI的Sora那样引人注目的新生成AI模型那么受关注。但它们是必不可少的。没有它们,现代AI模型很可能就不存在。
许多模型训练的数据必须被标记。为什么呢?标签可以帮助模型在训练过程中理解和解释数据。例如,用于训练图像识别模型的标签可能采取在物体周围标记的形式,称为“边界框”或描述图像中每个人、地方或物体的标题。
标签的准确性和质量显著影响训练模型的性能和可靠性。而标注是一项庞大的工作,需要对使用的更大更复杂的数据集进行成千上万甚至百万级别的标注。
所以你会认为数据标注员会受到良好对待,获得可持续生活工资,并享受建模工程师所拥有的同样福利。但实际情况往往相反——这是许多数据标注和标签化初创公司所推行的残酷工作条件的产物。
像OpenAI这样拥有数十亿美元现金的公司,依赖于在第三世界国家只支付几美元每小时的标注员。一些标注员接触到高度令人不安的内容,比如图形图像,但他们没有休假时间(通常是承包商),也没有获得心理健康资源的途径。
《纽约杂志》的一篇优秀文章揭开了Scale AI的面纱,该公司招聘了来自内罗毕和肯尼亚等国家的注释员。在Scale AI上的一些任务需要标注员连续工作多个八小时工作日 - 无休息时间 - 报酬仅为10美元。这些工人受制于平台的意愿。注释员有时会长时间没有工作,或者他们会被毫不客气地踢出Scale AI - 正如最近发生在泰国、越南、波兰和巴基斯坦的承包商那样。
一些注释和标记平台声称提供“公平贸易”工作。实际上,他们已将其作为品牌的核心部分。但正如麻省理工科技评论的凯特·凯所指出的,关于道德标注工作的定义没有规定,只有弱化工业标准,而公司自己的定义差异很大。
那么,该怎么办呢?除非出现重大的技术突破,否则为AI训练标注和标签数据的需求不会消失。我们可以希望这些平台自我规范,但更现实的解决办法似乎是制定政策。这本身是一个棘手的前景 - 但我认为,这是我们改变事情变得更好的最佳机会。或至少是开始。
以下是近几天一些备受瞩目的人工智能故事:
- OpenAI推出语音克隆器:OpenAI正在展示其开发的新AI工具Voice Engine,该工具能够让用户通过15秒的录音克隆某人的声音。但该公司选择暂不广泛发布,因为担心被滥用。 亚马逊继续投资Anthropic:亚马逊再次投资27.5亿美元用于扩大AI能力Anthropic,这是去年九月就留下的选项。 谷歌.org推出加速器:谷歌.org是谷歌的慈善部门,他们推出了一个新的2千万美元,为期六个月的项目,帮助资助发展利用生成式AI技术的非营利组织。 一个新的模型结构:AI初创公司AI21 Labs发布了一个生成式AI模型Jamba,采用了一种新颖的模型架构——状态空间模型,以提高效率。 Databricks推出DBRX:另一方面,Databricks本周发布了DBRX,这是一个类似于OpenAI的GPT系列和谷歌的Gemini的生成式AI模型。该公司声称它在许多流行的AI基准测试中取得了最前沿的成果,包括一些衡量推理能力的测试。 Uber Eats和英国AI监管:Natasha写到,Uber Eats的一名送餐员对抗AI偏见的斗争显示,在英国的AI监管下获得正义是艰难的。 欧盟选举安全指导:欧盟周二发布了旨在针对《数字服务法案》监管的大约二十个平台的选举安全指导草案,其中包括有关防止内容推荐算法传播生成式AI-based虚假信息(也称为政治deepfakes)的指导。 Grok得到升级:X公司的Grok聊天机器人将很快获得一个升级的基础模型Grok-1.5,同时X的所有高级订阅用户将获得Grok的访问权限。(之前Grok只提供给了高级订阅用户。) Adobe扩展Firefly:本周,Adobe推出了Firefly Services,一个包括20多种新的生成式和创意API、工具和服务。此外,它还推出了Custom Models,允许企业根据自己的资产调整Firefly模型——这是Adobe新的GenStudio套件的一部分。
更多的机器学习。
天气如何?人工智能越来越能告诉你这个问题。我几个月前注意到了一些针对每小时、每周和每个世纪的预测工作,但像所有人工智能一样,这个领域发展迅速。MetNet-3和GraphCast团队发布了一篇论文,描述了一个名为SEEDS的新系统,用于可扩展的集合包络扩散采样器。
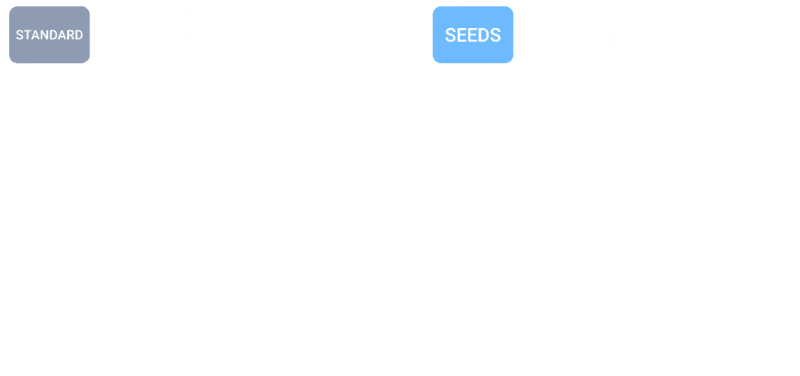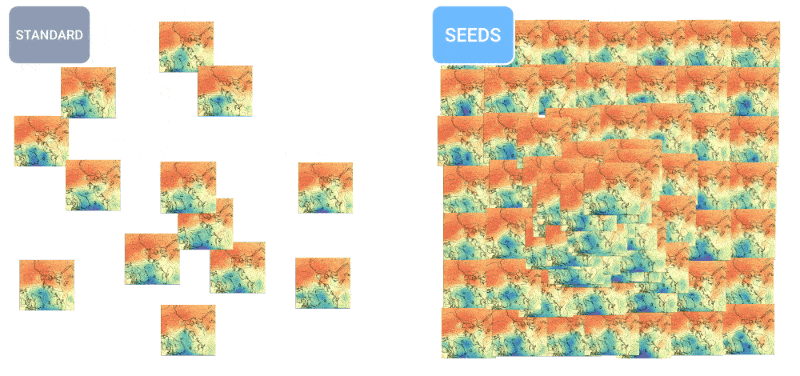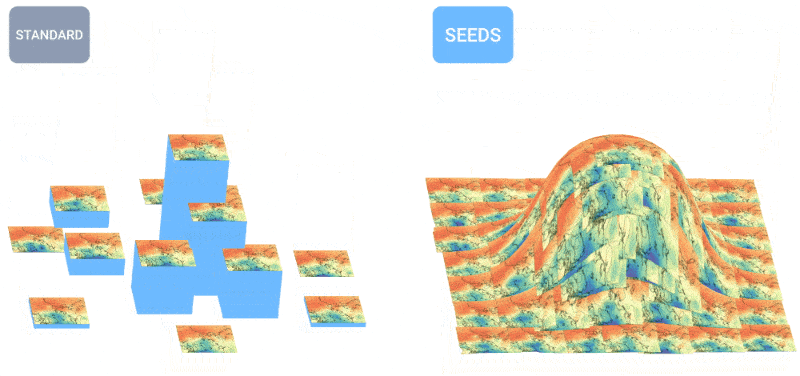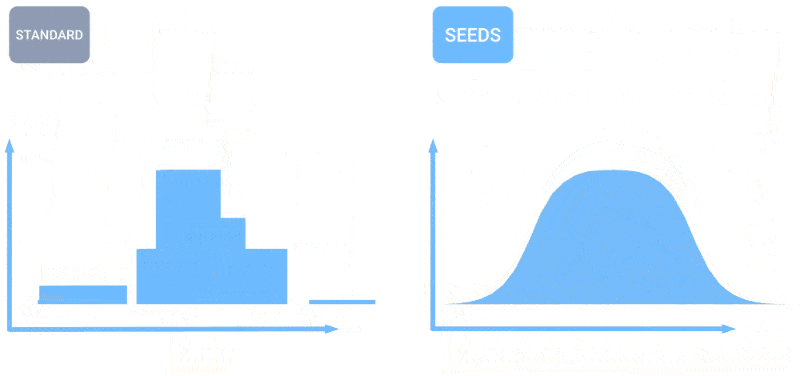
SEEDS使用扩散来生成“集合”,根据输入(例如雷达读数或轨道图像)为某个地区生成可信的天气结果,比基于物理的模型更快。随着集合数量的增加,它们可以涵盖更多的边缘情形(比如在100种可能情况中只发生1次的事件),对更可能出现的情况更有信心。
富士通也希望通过将人工智能图像处理技术应用于水下影像和水下自主车辆收集的激光雷达数据,更好地了解自然界。提高图像质量将使其他不太复杂的处理过程(如3D转换)在目标数据上更有效地运行。
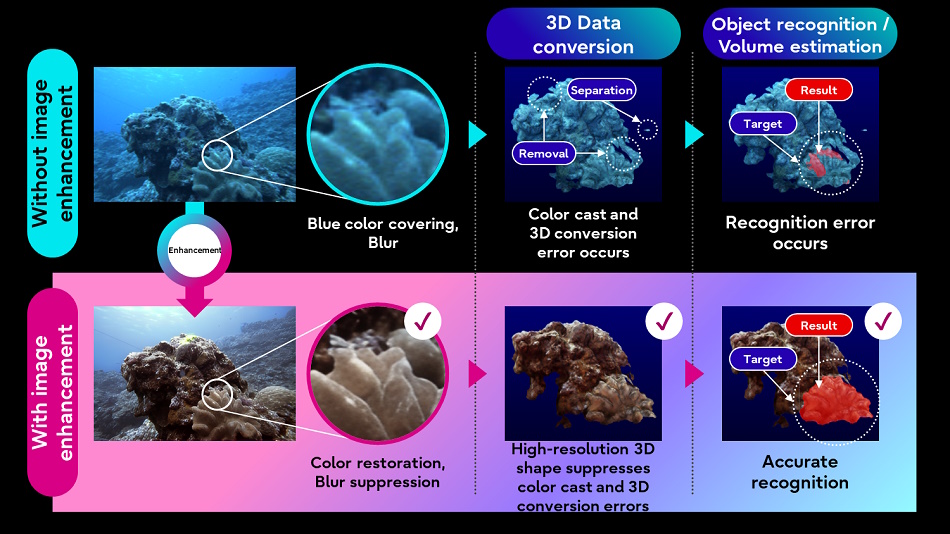
这个想法是建立一个“水的数字孪生体”,可以帮助模拟和预测新的发展。我们离那个目标还有很长的路要走,但是你得从某个地方开始。
研究人员发现,在LLM中,它们通过比预期更简单的线性函数来模仿智能。坦率地说,这些数学对我来说太复杂了(许多维度的向量东西),但麻省理工学院的这篇文章明确地指出,这些模型的召回机制是相当基本的。
即使这些模型非常复杂,是在大量数据上训练的非线性函数,并且非常难以理解,但有时候它们里面可能存在着非常简单的机制。共同主要作者埃文·埃尔南德斯说:“这就是一个例子。”如果你对技术更感兴趣,可以在这里查看论文。
这些模型失败的一种方式是不能理解上下文或反馈。即使是一个非常能干的LLM也可能“不理解”,如果告诉它你的名字是以某种方式发音,因为它们实际上并不知道或理解任何事情。在一些可能很重要的情况下,比如人与机器人的交互中,如果机器人表现出这种方式,可能会让人们感到不舒服。
迪士尼研究部门一直在研究角色之间的自动互动,而这篇关于姓名发音和重复利用的论文则是最近才发布的。从某种程度上看似乎很明显,但是当某人介绍自己时提取语音音位并进行编码,而不仅仅是使用书面姓名,这是一种聪明的方法。

最后,随着人工智能和搜索技术的日益交叉,值得重新评估这些工具的使用方式,以及这种不可思议的结合是否带来了新的风险。多年来,萨菲娅·乌莫加·诺布尔一直是人工智能和搜索伦理方面的重要声音,她的观点总是发人深省的。她曾经接受了加州大学洛杉矶分校新闻团队的专访,谈到了她的工作是如何发展的,以及我们为什么需要警惕搜索中的偏见和不良习惯。




