“动画任何人”标志着全息深度伪造技术的临近

好像静止图像的深度伪造还不够糟糕,我们可能很快就不得不应对生成的视频,其中包含敢于在网上发布自己照片的任何人:通过Anima Anyone,不良影响者可以比以往更好地操纵他人。
这种新的生成视频技术是由阿里巴巴集团智能计算研究所的研究人员开发的。与之前的图片到视频系统(如DisCo和DreamPose)相比,这是一个巨大的进步。这些系统在夏季令人印象深刻,但现在已经成为过去式了。
任何人都可以做的动画,并不是什么前所未有的,但已经跨越了“一般教学实验”和“近距离观察下才能受欢迎”的困难阶段。众所周知,下一阶段只是“足够好”,人们甚至不会费心仔细观察,因为他们认为它是真实的。这正是静态图像和文本交流目前所处的位置,对我们的现实感产生了严重影响。
像这样的图像到视频模型首先从一个参考图像中提取细节,如面部特征、图案和姿势,比如一张模特穿着待售服装的时尚照片。然后创建一系列图像,将这些细节映射到稍微不同的姿势上,这些姿势可以进行动作捕捉,或者从另一个视频中提取出来。
以前的模型显示这是可能实现的,但存在很多问题。幻觉是一个大问题,因为模型必须虚构合理的细节,比如当一个人转身时,袖子或头发可能如何运动。这会导致很多非常奇怪的影像,使得最终的视频远远不能令人信服。但这种可能性仍然存在,而Anima Anyone在很大程度上得到了改进,尽管仍然远离完美。
新模型的技术细节超出了大多数人的理解能力,但该论文强调了一个新的中间步骤,该步骤“使得模型能够在一致的特征空间中全面学习与参考图像的关系,这对于提高外观细节保存起到了显著的贡献。”通过改善基本和精细细节的保留,生成的图像在后续处理中有更强的真实性参照,从而得到更好的效果。
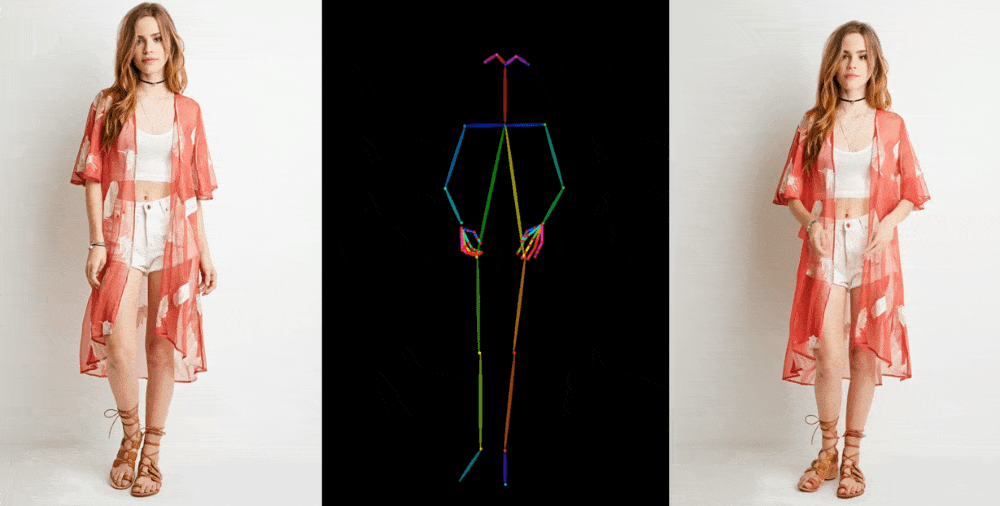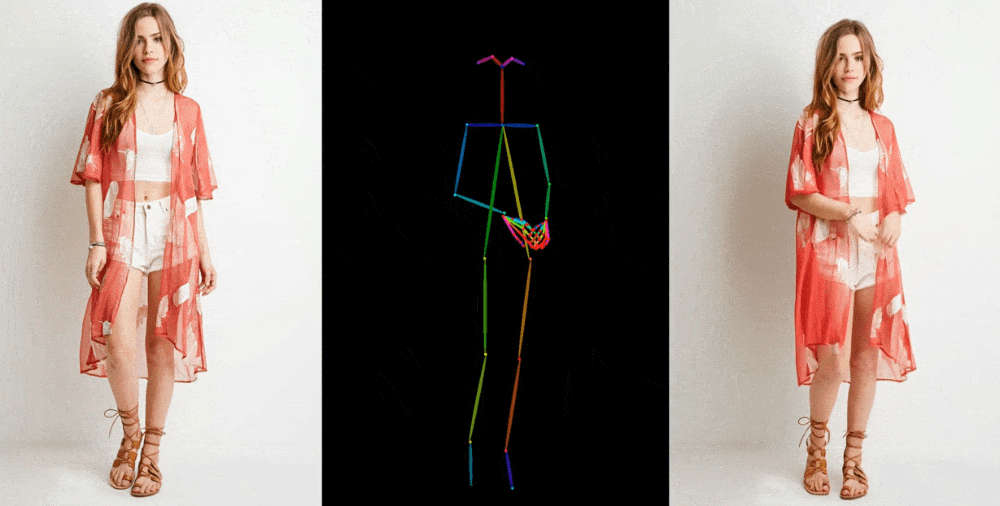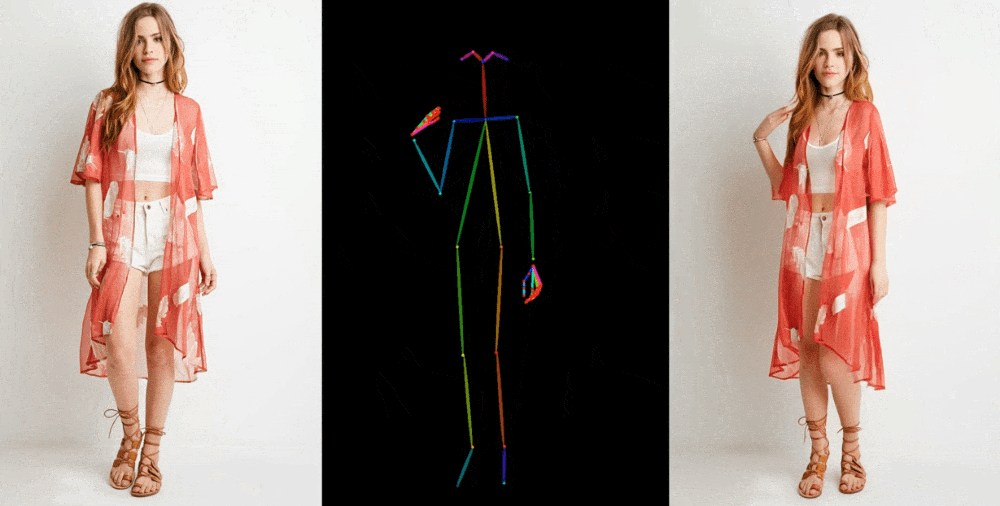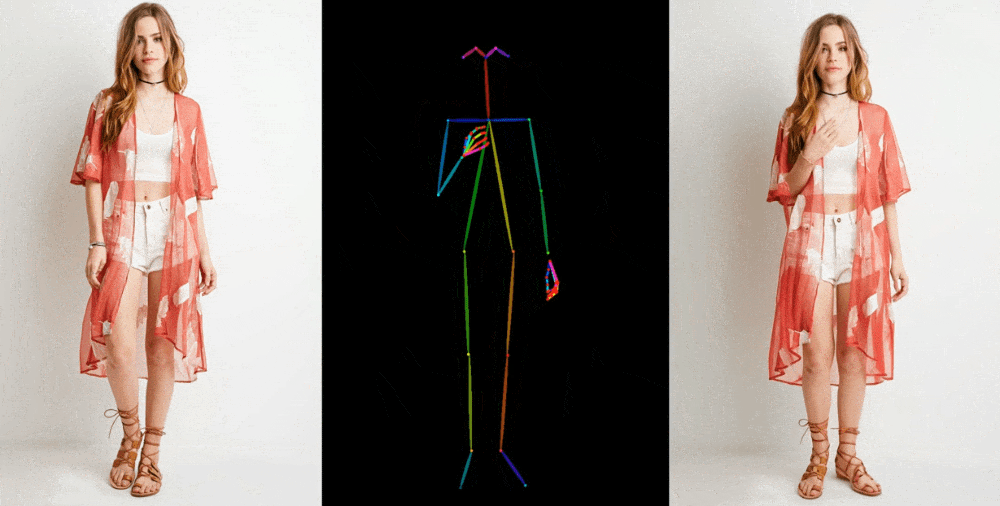
他们在一些场合展示他们的成果。时装模特采取任意姿势而不会使衣物变形或失去图案。二维动漫角色栩栩如生地跳舞。利昂内尔·梅西进行一些常见的动作。
它们远非完美 - 特别是对于生成模型来说,眼睛和手部造成了特别的问题。而且,最好表现出来的姿势是最接近原始的那些;例如,如果一个人转过身来,模型就很难跟上。但它是迈向先前的艺术水平的巨大飞跃,先前的艺术水平产生了更多的瑕疵或完全丢失了重要细节,如一个人的头发颜色或服装。
令人不安的是,想象一下,只要给恶意行为者(或制片人)一张高质量的你的照片,他们就能让你做任何事情,并结合面部动画和声音捕捉技术,同时还能让你表达任何情绪。然而目前,这项技术对于普通使用来说太复杂且存在缺陷,但在人工智能领域,事情往往不会保持不变太久。
至少团队还没有将代码释放到世界上。虽然他们有一个GitHub页面,但开发人员写道:"我们正在积极准备演示和代码以供公开发布。虽然我们当前无法确定一个具体的发布日期,但请确信我们提供演示和源代码的意愿坚定不移。"
当互联网突然充斥着舞蹈假视频时,情况会变得一团糟吗?我们将亲身体会,而且可能比我们期望的要早。




