作者的最新模型可以从图像中生成文本,包括图表和图形

随着生成式人工智能继续在头条中占主导地位,有时很难在炒作中找到实际有效的商业用例。Writer是一家位于旧金山的初创公司,致力于开发针对企业的生成式人工智能写作产品。今天,该公司宣布了其Palmyra模型的新能力,可以从图像中生成文本,包括图表,他们称之为Palmyra-Vision。
公司联合创始人兼首席执行官May Habib表示,他们做出了一个战略决定,专注于多模态内容,而能够从图像中生成文本是该战略的一部分。Habib告诉TechCrunch:“我们将专注于多模态输入,但输出为文本,即文本生成和通过文本传递的见解。”
在追随这颗引导之星的指引下,该公司决定分析图像,而不是制作它们(至少目前是这样)。她保留了从数据中创建图表和图形的权利,但目前并未进行这项工作。这次发布专注于从这类图像中生成文本。
据哈比布称,该公司采用多模型方法来生成棕榈视觉结果,每个模型在确定图像内容和生成文本时各自扮演特定角色,并且具有四个九的准确性。
这有很多用途,包括电子商务网站生成文本,从数千个变化的图片中填充网站最新的商品,而无需人工跟进每一个变化,或者自动解释图表和图形的主要要点。 另一个例子是合规性检查。 例如,一家制药公司可以使用Palmyra-Vision来执行自动FDA合规性检查,确保广告内容符合FDA规定如相关文件所述的惯例,在下面的例子中。
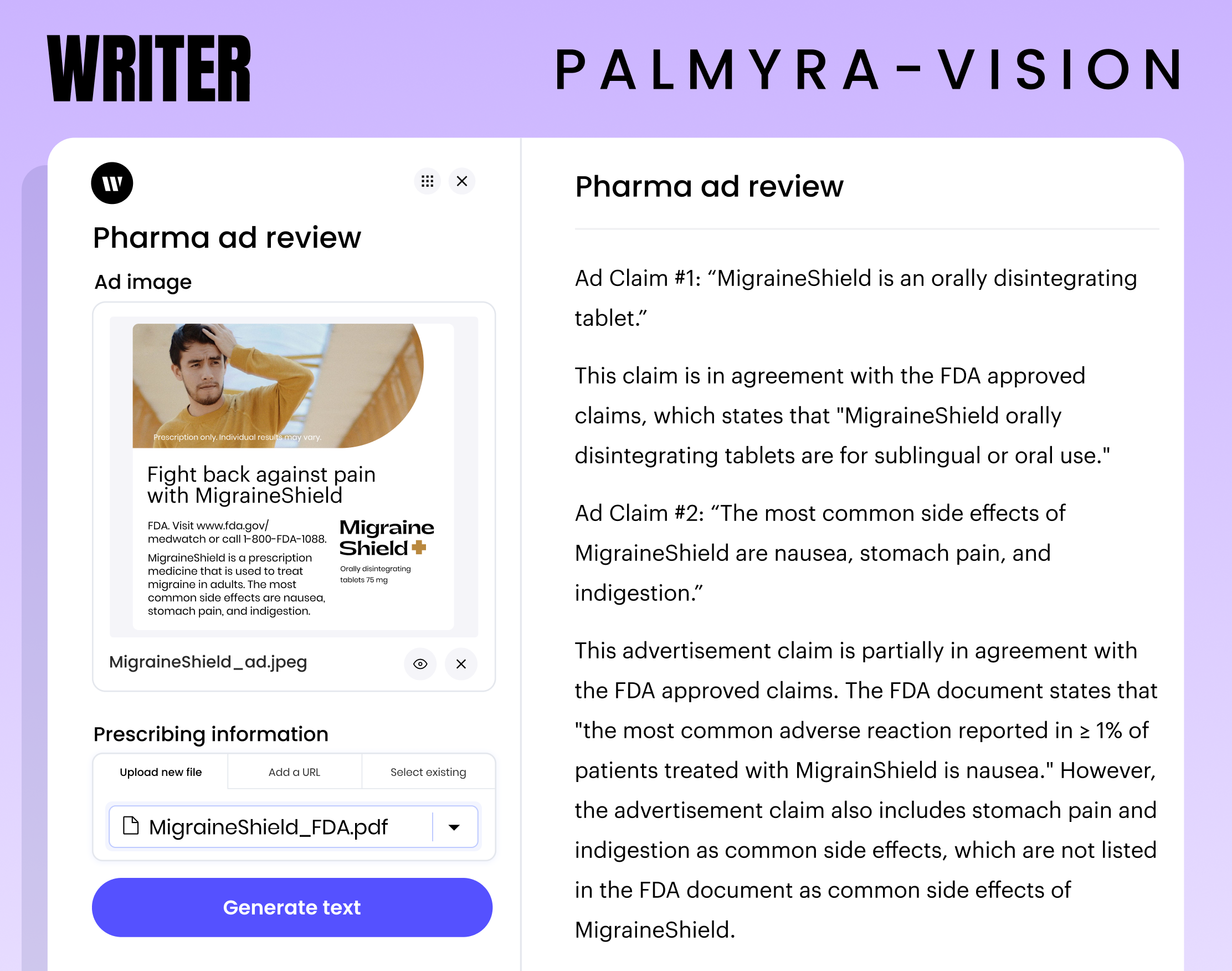
最终,该产品可以将手写笔记进行解释和总结成文本,但哈比布表示,需要对模型进行训练以适应个人使用案例,比如医疗或保险,从而确保准确性。
Habib表示,她不推荐在工作流程中使用这些工具时不经人类审核。她认为这是绝对必要的,因为任何模型都可能会产生幻觉(虚构)或者仅仅得出错误的事实,重要的是让人们检查结果。尽管他们始终向每个客户推荐这样做,大多数客户此时都理解了,但她认为最终需要更多的自动化工作流程,以便持续、一致地应用在各个客户身上,她表示公司正在朝着这个方向努力。
根据Crunchbase的数据,该公司迄今已筹集了1.26亿美元。目前正与大型云基础设施平台进行合作谈判,以便扩大公司规模。该公司最近一轮融资是去年9月领投的1亿美元B轮融资。
从今天开始,最新的帕尔米拉版本具有图像转文本功能。




