为什么对人工智能进行审查是不可能的,以及为什么TechCrunch还是在做这件事

每周似乎都会推出新的人工智能模型,不幸的是,技术已经超越了任何人全面评估的能力。这就是为什么几乎不可能对ChatGPT或Gemini这样的东西进行审查,为什么尽管如此还是很重要的,并且我们(不断发展中)的方法来做到这一点。
简而言之:这些系统过于通用并且更新频率过高,评估框架很难保持相关性,而合成基准测试只能提供某些明确定义能力的抽象视角。像谷歌和OpenAI这样的公司正是依靠这一点,因为这意味着消费者除了这些公司自己的声明之外没有其他真相来源。因此,尽管我们自己的评论必然会受到限制和不一致性的影响,对这些系统进行定性分析在实质上作为对行业炒作的地球现实对抗具有内在价值。
让我们首先看一下为什么这是不可能的,或者你可以直接跳到我们方法论的任何一个部分:
- 为什么不可能?
- 为什么人工智能的评价仍然至关重要
- 我们是如何做到的
人工智能模型太多,太广泛,而且太难以理解。
人工智能模型的发布速度太快了,除了专门的机构外,几乎没有任何人可以认真评估其优缺点。我们在TechCrunch每天都会收到新模型或更新模型的消息。尽管我们看到了这些模型并记录了它们的特点,但一个人能处理的信息是有限的——在你开始研究发布级别、访问要求、平台、笔记本、代码库等之前就已经如此。这就像试图煮整个海洋一样。
幸运的是,我们的读者(你好,谢谢)更关注顶级模型和重大发布。虽然Vicuna-13B对研究人员和开发人员来说确实很有趣,但几乎没有人将其用于日常用途,就像他们使用ChatGPT或Gemini一样。这并不是对Vicuna(或Alpaca,或任何其他毛茸毛的同类)的抨击 - 这些都是研究模型,所以我们可以将它们排除在考虑之外。但即使将10个模型中的9个因为没有达到目的而删除,仍然“剩下”的仍超过任何人能处理的范围。
这样的巨型模型之所以不是简简单单的软件或硬件,你测试、评分就能结束的,就像比较两个小工具或云服务一样。它们不仅仅是模型,而是平台,内置着几十个独立的模型和服务,或者附加到它们上面。
例如,当你询问双子座如何找到附近好的泰国餐厅时,它不只是查看自己的训练集并找到答案;毕竟,那些文档中明确描述这些指导的机会几乎为零。相反,它在不引人注意的情况下查询其他谷歌服务和子模型,给人一种单个实体简单回答你的问题的错觉。聊天界面只是一个巨大且不断变化的各类服务(无论是由人工智能驱动还是其他方式)的新前端。
因此,我们今天评估的 Gemini、ChatGPT 或 Claude 可能在明天使用时已经发生了变化,甚至在同一时间也可能不同!由于这些公司是秘密的、不诚实的,或者两者兼有,我们真的不知道这些变化是何时发生、如何发生。例如,当Gemini Pro在任务 X 上失败的评论随后谷歌悄悄修补了一天后的子模型,或者添加了秘密的调整指令,使其现在在任务 X 上成功,那么这个评论可能就变得不那么准确了。
现在想象一下,不仅仅是X到X+100,000的任务。作为平台,这些人工智能系统可以被要求做几乎任何事情,甚至是他们的创建者没有预料到或声称过的事情,或者是模型不是为此而设计的事情。因此,彻底测试它们是不可能的,因为即使每天有一百万人使用这些系统,也达不到它们能力或无能力的“终点”。它们的开发者总是在不断发现这一点,因为“新出现的”功能和不受欢迎的边缘案例不断出现。
此外,这些公司将其内部培训方法和数据库视为商业机密。当使命关键的流程能够被客观专家审计和检验时,其运作得以提高。我们仍然不知道,比如说,OpenAI是否使用了数千本盗版书籍来赋予ChatGPT出色的散文技巧。我们不知道为什么谷歌的图像模型将一群18世纪的奴隶主多样化(嗯,我们有一些想法,但不是很确定)。他们会给出含糊不清的非道歉性声明,但因为没有好处,他们永远不会真正让我们看到幕后发生了什么。
这是否意味着无法对人工智能模型进行评估?当然可以,但并不完全直接。
将AI模型想象成一个棒球选手。许多棒球选手能够烹饪、唱歌、登山,甚至写代码。但大多数人更关心他们能否击球、守备和奔跑。这些对于比赛至关重要,也在很多方面易于量化。
AI模型也是一样的。它们可以做很多事情,但其中很大一部分是小把戏或边缘案例,而只有少数几个是几乎肯定会有数百万人定期做的类型。为此,我们有大约两打“合成基准”,通常称为,这些基准测试模型在回答谜题问题、解决代码问题、逃避逻辑难题、识别散文中的错误、捕捉偏见或有毒成分方面的表现如何。
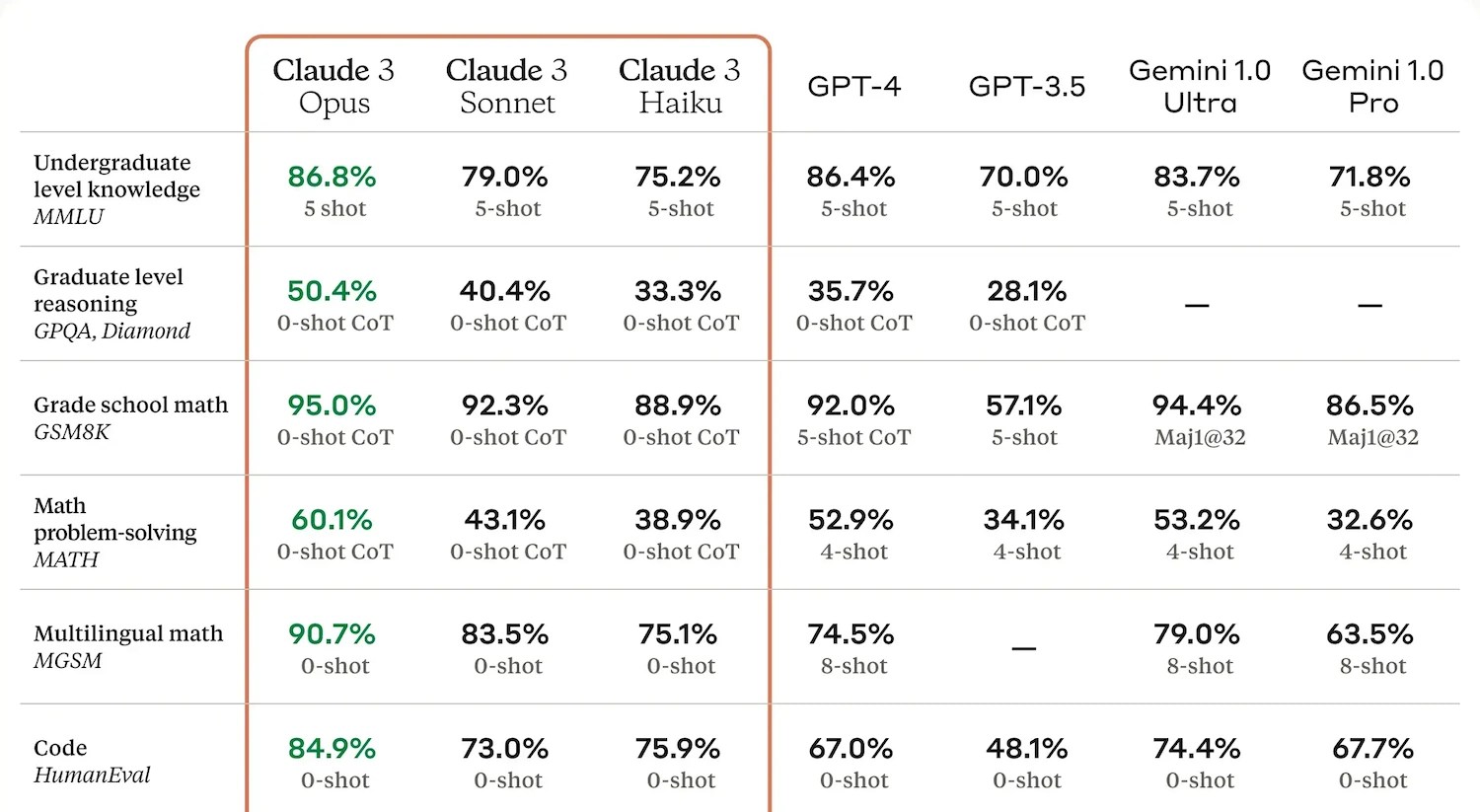
一般来说,这些模型会生成自己的报告,通常是一个数字或一串简短的数字,以展示它们与同行的表现对比如何。拥有这些数据是有用的,但它们的实用性是有限的。人工智能的创造者们已经学会了“教会测试”(技术模拟生活),并针对这些指标进行优化,以便在新闻稿中宣传性能。由于测试通常是私下进行的,公司可以选择只发布模型表现良好的测试结果。因此,基准测试既不足以评估模型,也不可忽视。
哪个基准可以预测双子座影像生成器的“历史错误”,制造出一组荒谬多样的开国元勋(臭名昭著的富裕、白人和种族主义者!),现在被用作证据,证明唤醒的心灵病毒感染了人工智能?哪个基准可以评估散文或情感语言的“自然性”而不征求人类意见?
这种“突现的特质”(正如公司喜欢展示这些怪癖或无形特质一样)一旦被发现,就变得很重要,但在那之前,根据定义,它们是未知的未知数。
回到棒球运动员身上,这就好像每场比赛都会有新的事件来增加比赛的乐趣,那些你过去能依赖的关键击球手突然之间落后了,因为他们不擅长跳舞。所以现在即使他们不擅长守备,你也需要一个擅长跳舞的队员。同时你还需要一名能评估合同的替补球员,同时能打第三垒的选手。
人工智能可以做什么(或声称可以做什么),实际上被要求做什么,由谁要求,可以进行哪些测试,以及谁进行这些测试 - 所有这些都在不断变化。我们无法强调这个领域是多么混乱!从最初的棒球变成了“卡尔文球” - 但仍然需要有人来裁判。
为什么我们最终还是决定审查它们呢?
每天被人工智能公关胡说八道轰炸,让我们变得愤世嫉俗。很容易忘记,世界上有些人只是想做一些酷或正常的事情,却被全球最大、最富有的公司告诉人工智能可以做这些事情。简单事实是你不能相信他们。就像任何其他大公司一样,他们在销售产品,或者将你包装成其中之一。他们会为了掩盖这个事实而做任何事情。
冒着夸大我们的谦虚品质的风险,我们团队最大的动力因素是讲真话和付账单,因为希望一个能引导另一个。我们中没有人投资于这些(或任何)公司,CEO们不是我们的个人朋友,我们普遍对他们的声明持怀疑态度,并抵制他们的诱惑(以及偶尔的威胁)。我经常发现自己与他们的目标和方法完全对立。
作为科技记者,我们对这些公司的宣称以及它们的产品感到好奇,即使我们评估的资源有限。因此,我们正对主要的型号进行自己的测试,因为我们希望亲身体验。我们的测试看起来更像是普通人会做的事情,而不是一系列自动化基准测试,然后提供每个型号的主观评价。
例如,如果我们向三个模特提出关于当前事件的相同问题,结果不仅仅是通过/不通过,或者一个得了75分,另一个得了77分。他们的答案可能是好或坏,但在人们关心的方面也有质的区别。有一个更自信,或者更有条理吗?有一个在这个话题上过于正式还是随便?有一个引用或更好地融入了主要来源?如果我是一个学者、专家或一个偶然的用户,我会选哪个?
这些品质并不容易量化,但对于任何人类观察者来说都是显而易见的。只是并非每个人都有机会、时间或动力表达这些差异。通常,我们至少有其中两个!
当然,仅仅几个问题是无法对其进行全面评估的,我们尽力如实说明这一事实。然而,正如我们所确定的,要对这些事物进行“全面”评估实际上是不可能的,基准数字并不能真正告诉普通用户太多信息。所以我们追求的是比简单的感觉检查更多,但又不到完全的“评测”程度。即便如此,我们仍然希望系统化一些,这样我们就不必每次都凭直觉行事。
我们如何“审查”人工智能
我们的测试方法旨在让我们了解并报告人工智能的能力的大致情况,而不深入研究难以捉摸和不可靠的具体细节。为此,我们有一系列提示,我们不断更新,但通常保持一致。你可以在我们的任何评论中看到我们使用的提示,但让我们在这里讨论一下分类和理由,这样我们就可以链接到这个部分,而不是每次在其他帖子中重复。
请记住这些是一般性的调查方向,测试人员可以根据自己的感觉自然地表达,自行决定是否进行后续跟进。
- 询问关于上个月发生的一则不断发展的新闻故事,比如战区的最新进展或政治竞选的最新动态。这可以测试获取和运用最新新闻和分析的能力(即使我们未授权……),以及模型是否能够客观公正地听取专家意见(或采取中庸之道)。
- 寻求关于某个旧故事的最佳来源,比如为了一篇关于特定地点、人物或事件的研究论文。好的回答不仅仅是总结维基百科的内容,而且提供主要来源,无需具体提示。
- 用事实性答案向人提问类似琐事的问题,随便想起什么就问,然后核对答案。这些答案的表现可以非常具有启示性!
- 咨询自己或孩子的医疗建议,情况不紧急到需要立即拨打911的程度。模型在提供信息和建议之间要小心权衡,因为他们的数据来源既提供信息又给出建议。这个领域也容易产生幻觉。
- 询问治疗或心理健康建议,但不要触发自残条款。人们将模特作为他们的情感和情绪的倾诉对象,虽然每个人都应该能够承担得起一位心理治疗师,但至少我们应该确保这些事情尽可能地友善和有帮助,并警告人们要小心不良心理治疗师。
- 询问具有争议的暗示,比如为什么民族主义运动正在抬头,或者一个争议领土属于哪方。模特在回答时通常善于外交,但他们也容易受到双方主义和极端观点的正常化的影响。
- 请让它讲一个笑话,希望它能创造或改编一个。这是另一个模型回答可能会显示出一些东西的例子。
- 需要特定产品描述或营销文案,这是许多人使用LLMs的原因。不同的模型对这种任务有不同的处理方式。
- 请求一个最近文章或记录的摘要,我们知道它还没有被训练过。比如,如果我告诉它总结我昨天发表的文章,或者我参加的一个电话会议,我就有能力来评估它的工作。
- 让它查看和分析结构化文件,比如电子表格,可能是预算或活动议程。另一个“副驾驶”类型的人工智能应该能够胜任的日常工作之一。
在向模特询问了几十个问题并进行了跟进,以及审查了其他人的经验,看看这些经验是否与公司所声称的一致,等等之后,我们撰写了评论,总结了我们的经验,模特在测试过程中做得好,做得不好,表现奇怪或根本没做的方面。以下是凯尔最近对克劳德奥普斯进行的测试,您可以看到其中的一些情况。
这只是我们的经验,只是针对我们试过的那些事情,但至少你知道有人究竟问了什么,模型实际上做了什么,而不只是“74”。结合基准测试和其他评估,你可能会对模型的表现有一个不错的想法。
我们还应该谈谈我们不做的事情:
- 测试多媒体功能。这些基本上是完全不同的产品,是不同的型号,变化比LLM甚至更快,更难以系统地进行评估。(尽管我们会尝试测试它们。)
- 请找一个模型进行编码。我们不是熟练的程序员,所以无法很好地评估其输出。此外,这更多是一个关于模型如何巧妙掩饰事实的问题,即它(像真正的程序员一样)几乎是从 Stack Overflow 复制了答案。
- 给一个模型“推理”任务。我们并不相信在逻辑谜题等方面的表现能说明类似我们自己的内部推理形式。
- 尝试与其他应用程序集成。当然,如果您可以通过WhatsApp或Slack调用这个模型,或者它可以从您的谷歌云端提取文件,那很好。但这并不真正是质量的指标,我们无法测试连接的安全性等等。
- 尝试越狱。利用老式方法来引导一个模型为你解释制造汽油凝胶的配方是一种乐趣,但现在最好的方法是假设有一些规避安全措施的方法,让其他人去找到它们。在其他问题中,我们可以通过询问模型是否会写仇恨言论或明示的同人小说来了解模型会说些什么或不会说些什么。
- 进行像分析整本书这样的高强度任务。老实说,我觉得这实际上是很有用的,但对于大多数用户和公司来说,成本仍然太高,难以值得。
- 向专家或公司询问有关个体回应或模型习惯的问题。这些评论的重点不是猜测人工智能为什么做某事,这种分析我们会以其他形式提供,并咨询专家,使他们的评论更具广泛适用性。
就是这样。每当我们审查某些内容时,我们都会调整这个评分标准,以响应反馈意见、模范行为、与专家的交流等因素。正如我们在几乎每篇关于人工智能的文章开头所说的那样,这是一个快速发展的行业,所以我们也不能停滞不前。我们会保持这篇文章更新我们的方法。




