本周人工智能动态:OpenAI在高等教育领域找到合作伙伴

跟上一个迅速发展的人工智能行业是一项艰巨的任务。因此,在还没有人工智能可以代替你之前,这里有一组方便的报道,涵盖了最近的机器学习领域新闻,还有一些我们没有单独报道的重要研究和实验。
本周在AI领域,OpenAI签下了第一家高等教育客户:亚利桑那州立大学。
亚利桑那州立大学将与OpenAI合作,为该大学的研究员、员工和教职员工带来ChatGPT,即OpenAI的AI聊天机器人。他们计划在二月份进行一个公开挑战,邀请教职员工提交使用ChatGPT的创意想法。
开放AI与亚利桑那州立大学的协议显示出了人工智能在教育领域观念的变化,因为技术的进步远远超过了课程的跟进速度。去年夏天,学校和大学匆忙禁用了ChatGPT,担心存在抄袭和不实信息问题。此后,一些学校已撤销禁令,而其他一些学校开始举办关于GenAI工具及其在学习中潜力的研讨会。
对于GenAI在教育中的角色问题,争论还不太可能很快解决。但是 — 就我来说 — 我发现自己越来越支持这一观点。
是的,GenAI是一个糟糕的总结者。它存在偏见和有害内容。它会杜撰事实。但它也可以被用于正面用途。
考虑一下像ChatGPT这样的工具可能如何帮助在做作业时遇到困难的学生。它可以逐步解释数学问题,生成论文大纲。或者可以提供一个问题的答案,而在谷歌上搜索可能需要更长时间。
现在,对作弊问题存在合理的担忧,或者至少可以说是在当前的课程框架内被视为作弊的行为。有传闻称,学生中尤其是大学生在撰写论文和参加闭卷考试时,使用ChatGPT来撰写大量文字。
这并不是个新问题——代写服务已经存在了很长时间。但一些教育工作者争论说,ChatGPT大大降低了准入门槛。
有证据表明这些恐惧是夸大的。但暂时抛开这个问题,我认为我们应该退一步,考虑是什么原因让学生们首先去作弊。学生们通常因成绩而受到奖励,而不是因为努力或理解力。激励结构有问题。难怪孩子们把学校作业看作是需要打勾的任务,而不是学习的机会。
让学生们使用人工智能生成的课程,让教育工作者探索如何利用这项新技术,以孩子们容易接受的方式进行教学。我对教育改革没有太多希望,但也许人工智能可以成为启动教学计划的起点,让孩子们对以前从未涉足的学科感到兴奋。
以下是最近几天里一些值得关注的人工智能故事:
微软的阅读导师:本周微软将其提供个性化阅读训练的人工智能工具“阅读导师”免费提供给所有拥有微软账号的用户。
音乐中的算法透明度:欧盟监管机构呼吁制定法律,强制音乐流媒体平台提供更大的算法透明度。他们还希望解决由人工智能生成的音乐和深度伪造问题。
美国航天局的机器人:美国航天局最近展示了一个自组装的机器人结构,德文写道,这可能会成为离地行动的关键部分。
三星Galaxy,现在由AI驱动:在三星Galaxy S24发布会上,该公司展示了AI如何改善智能手机体验的各种方式,包括通话的实时翻译,建议的回复和操作,以及使用手势进行谷歌搜索的新方法。
DeepMind的几何解决方案:这周,Google AI研发实验室DeepMind揭示了AlphaGeometry,一个据实验室称之为能够解决与国际数学奥林匹克竞赛金牌得主一样多的几何问题的AI系统。
OpenAI和众包:在其他OpenAI的消息中,这家初创公司正在组建一个新团队,名为“协同定位”,以实现公众对于确保其未来人工智能模型“与人类价值观一致”的想法。与此同时,它也改变了其政策,允许其技术被用于军事应用。(这可真是一种混合信息传递啊。)
Copilot的专业版计划:微软推出了面向消费者的Copilot专业版计划,这是该公司基于人工智能技术和内容生成技术的产品组合的总称,并放宽了企业级Copilot服务的资格要求。此外,微软还为免费用户推出了新功能,包括Copilot智能手机应用程序。
欺骗性模型:大多数人类都学会了欺骗其他人类的技巧。那么AI模型能否也学会相同的技巧呢?是的,根据人工智能初创企业Anthropic的一项最新研究,答案似乎是肯定的——而且令人恐惧的是,它们在这方面表现异常出色。
特斯拉的分阶段机器人演示: 特斯拉的埃隆·马斯克(Elon Musk)推出的Optimus人形机器人正在进行更多的活动——这次是在一个开发设施的桌子上折叠一件T恤。但实际上,在当前阶段,这个机器人并不是自主的。
更多的机器学习
阻碍诸如AI卫星分析之类技术广泛应用的其中一个问题是需要训练模型以识别可能是相当奥妙的形状或概念。识别建筑物的轮廓:很容易。识别洪水后的碎片区域:就不那么容易了!瑞士EPFL的研究人员希望通过一个名为METEOR的程序来简化此过程。
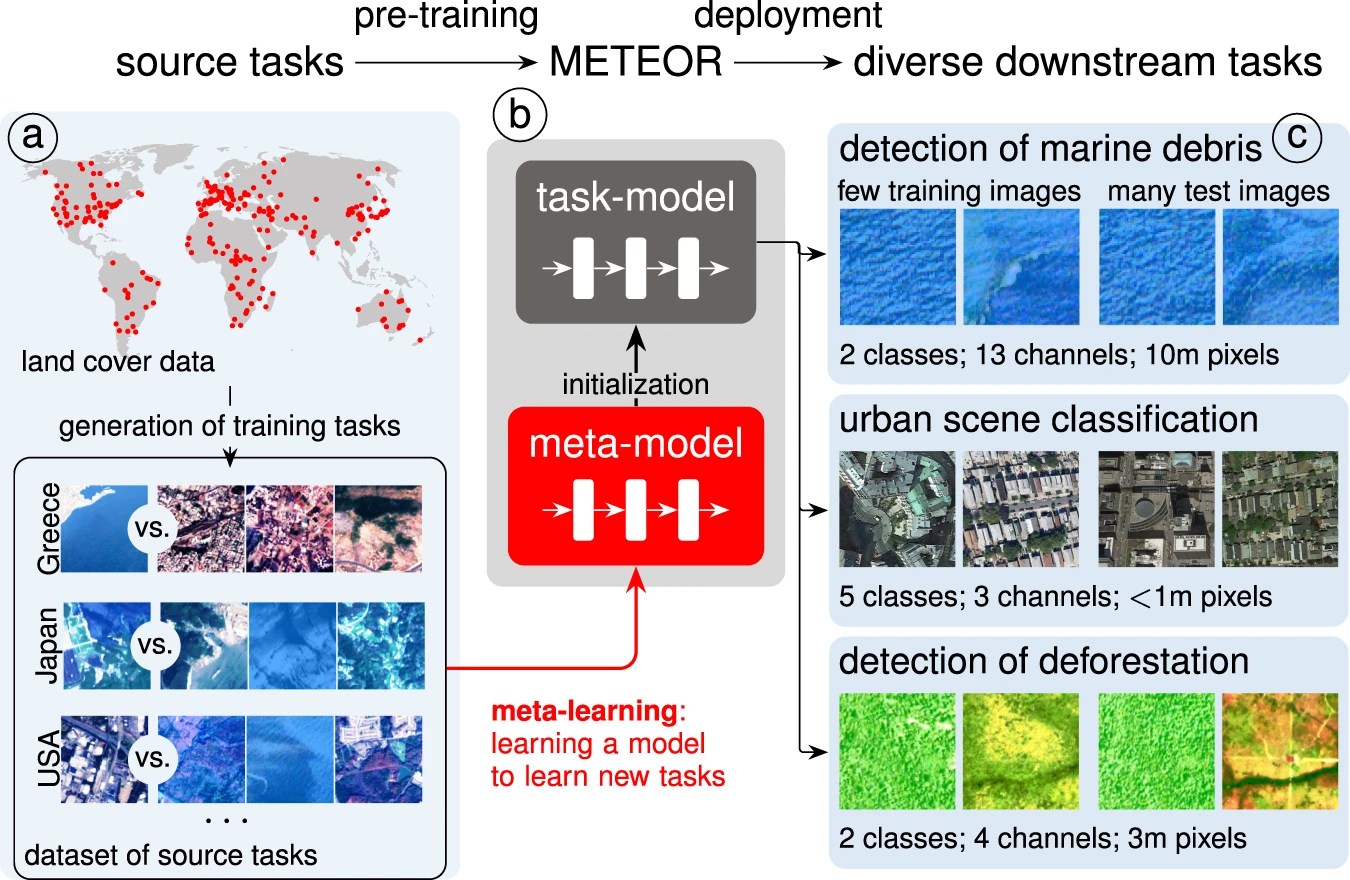
该项目的负责人之一Marc Rußwurm表示:“环境科学中的问题在于往往无法获取到足够大的数据集来训练满足我们研究需求的AI程序。”他们新的训练结构允许使用仅有四到五个代表性图像来训练一个识别算法以完成新的任务。其结果与使用更多数据进行训练的模型相当。他们计划将该系统从实验室推广到产品,并为普通人(也就是非AI专家研究人员)提供一个用户界面来使用它。您可以在这里阅读他们发表的论文。
走另外一条路——创作图像——是一项激烈研究的领域,因为有效地实现这一点可以减轻生成人工智能平台的计算负荷。最常见的方法称为扩散,它逐渐将纯噪声源转化为目标图像。洛斯阿拉莫斯国家实验室有一种新的方法,他们称之为“黑暗扩散”,它从一个纯黑图像开始。
这消除了噪音的需求,但真正的进展在于该框架是在“离散空间”中进行,而不是连续的,大大减少了计算负荷。他们说这种方法表现良好,成本更低,但离广泛发布还有很长的路要走。我没有资格评估这种方法的效果(数学对我来说太复杂了),但国家实验室不会毫无理由地夸大其词。我会向研究人员询问更多信息。
人工智能模型正在自然科学领域广泛出现,它们能够从噪声中筛选出信号,既产生新的洞察力,又节省了研究生进行数据录入所花费的时间和金钱。
澳大利亚正在将Pano AI的野火探测技术应用于其重要的林业区域“绿色三角地带”。很高兴看到像这样的创业公司得到应用——不仅可以帮助预防火灾,还为林业和自然资源管理部门提供宝贵的数据。对于野火(或者他们称之为丛林火灾)来说,每一分钟都很重要,因此提前通知可能是避免数以千计公顷土地受损的关键。

洛斯阿拉莫斯再次被提及(我在查看笔记时意识到)因为他们也正在研究一种新的人工智能模型,用于估计永久冻土的消退。现有模型的分辨率较低,以约1/3平方英里的区域为单位预测永久冻土水平。这当然是有用的,但更详细的数据可以减少在较大尺度上可能看起来是100%永久冻土的区域,但在更接近的观察下明显不是的误导性结果。随着气候变化的发展,这些测量数据需要更加准确!
生物学家们正在寻找有趣的方式测试和使用人工智能(AI)或与AI相关的模型在该领域的许多子领域中。在最近一次由我的朋友在GeekWire写的会议上,展示了跟踪斑马、昆虫甚至单个细胞的工具。
在物理和化学领域,美国阿贡国家实验室的研究人员正在研究如何最好地包装氢作为燃料使用。自由氢因难以收容和控制而闻名,因此将其与特殊助剂分子结合可以使其保持稳定。问题在于氢与几乎所有物质都能发生结合,因此有数以亿计的助剂分子可能性。但通过大量数据进行筛选是机器学习的专长。
该项目的Hassan Harb说:“我们正在寻找能长时间储存氢气的有机液态分子,但它们又不会储存得太牢固,以至于无法轻松地按需释放。”他们的系统筛选了1600亿个分子,并通过使用人工智能筛选方法,他们能够每秒查看300万个分子,所以整个最终过程大约花了半天的时间。(当然,他们使用了相当庞大的超级计算机。)他们确定了41个最佳候选者,这对于实验组来说只是一个微不足道的数字。希望他们能找到一些有用的东西——我不想在我下一辆汽车中处理氢气泄漏的问题。
最后,需要注意的是,尽管一项在《科学》杂志上的研究发现,用于预测患者对某些治疗方法反应的机器学习模型在其训练样本群体中非常准确,但在其他情况下,它们基本上没有任何帮助。这并不意味着它们不应该被使用,但它支持业内很多人一直在说的观点:人工智能不是万能药,必须在每个新的人群和应用中进行彻底测试。




