谷歌Deepmind训练了一个可玩视频游戏的人工智能,成为您的合作伙伴

玩游戏的AI模型已经发展了几十年,但通常专门研究一种游戏,并且总是为了赢而玩。谷歌Deepmind的研究人员在他们最新创造的模型上有不同的目标:该模型学会像人类一样玩多款3D游戏,同时也尽力理解并根据您的口头指示行动。
当然有“AI”或计算机角色可以做这种事情,但它们更像游戏的特征:NPCs,你可以使用游戏内的正式命令来间接控制。
Deepmind的SIMA(可扩展教学多世界智能)并没有任何访问游戏内部代码或规则的方式;相反,它是通过观看人类玩家的游戏录像来进行训练的。通过这些数据,以及数据标注员提供的注释,模型学会了将某些视觉表现与动作、对象和交互联系起来。他们还记录了玩家互相指导在游戏中做事情的视频。
例如,它可能会从屏幕上像素如何移动的特定模式中学习到这是一种叫做“向前移动”的动作,或者当角色靠近类似门的物体并使用门把手状的物体时,那就是“打开”一扇“门”。像这样简单的事情,需要几秒钟的任务或事件,但不仅仅是按一下键盘或识别一些东西。
这些培训视频是在多款游戏中制作的,从《瓦尔海姆》到《模拟山羊3》,相关开发人员参与并同意将其软件用于此用途。研究人员在与新闻界通话中表示,其中一个主要目标是看看是否训练人工智能玩一组游戏能够使其有能力玩其他未曾见过的游戏,这个过程被称为泛化。
答案是肯定的,但有一些前提条件。用多个游戏训练的 AI 代理在没有接触过的游戏中表现更好。但当然,许多游戏涉及特定和独特的机制或术语,这将使最充分准备的 AI 陷入困境。但除了缺乏训练数据之外,没有任何阻止模型学习这些内容的。
这在一定程度上是因为,虽然游戏中有很多术语,但实际上玩家有影响游戏世界的“动词”只有那么多。无论你是建立一个简易住所,搭建一个帐篷还是召唤一个魔法庇护所,你实际上都是在“建造一座房子”,对吧?所以,目前代理程序识别的几十种基本元素的地图确实很值得细看:
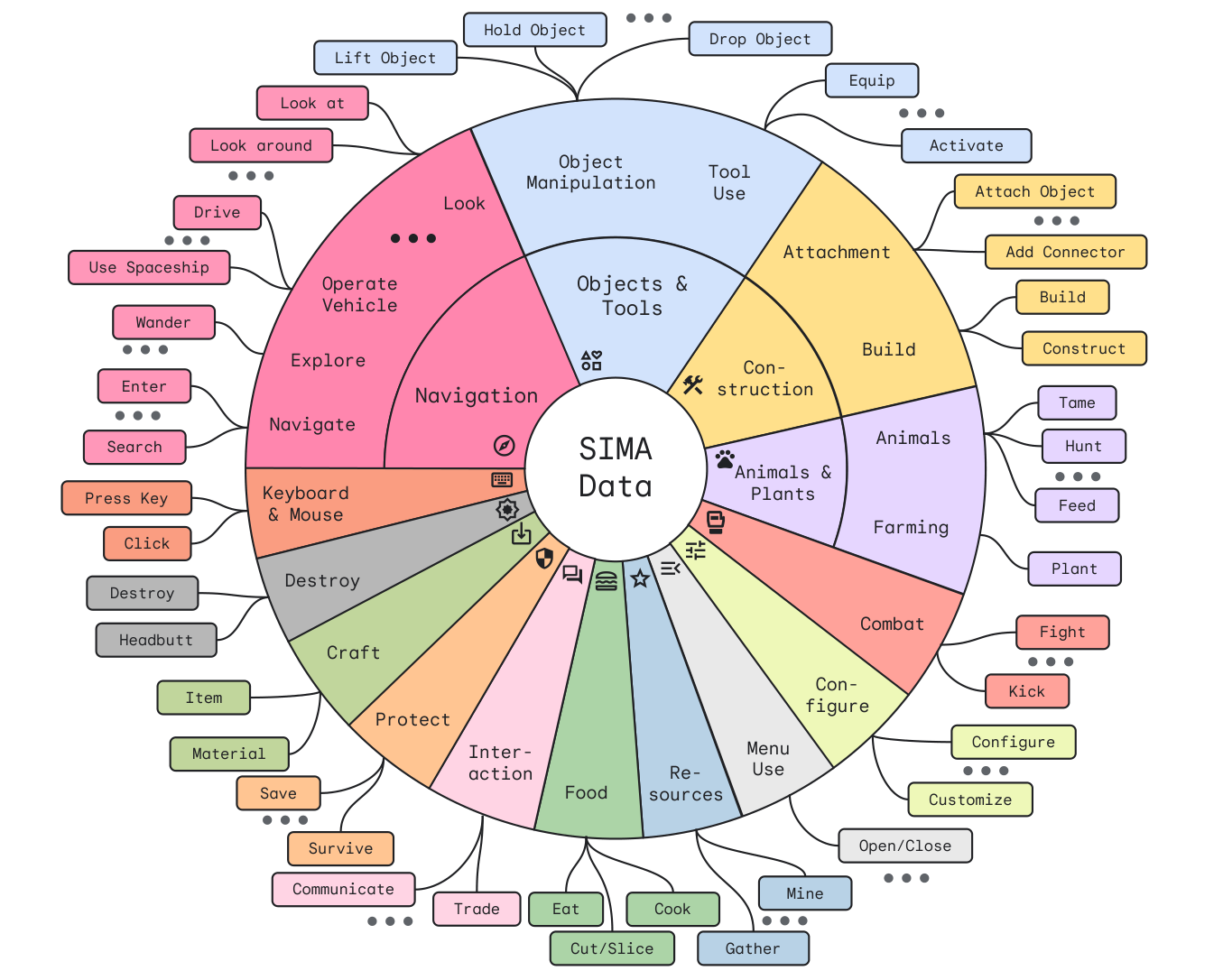
研究人员的雄心壮志不仅在于基本推进基于代理的人工智能,还在于创造比我们今天那些僵硬、硬编码的游戏伴侣更自然的人工智能。
“与其和一个超人类智能体对战,不如有一些合作的SIMA玩家在你身边,你可以给他们指令,”项目负责人之一Tim Harley说道。
自从他们开始玩游戏时,他们看到的只是游戏屏幕上的像素,他们必须学会如何做事情,就像我们所做的一样 - 但这也意味着他们可以适应并产生新的行为。
您可能会好奇,这种方法与制作代理型AI的常见方法——模拟器方法相比如何,后者是在3D模拟世界中进行广泛实验,运行速度远快于真实时间,大多数情况下模型是无人监督的,这样可以直观地学习规则,并设计行为而不需要太多标注工作。
“传统的基于模拟器的代理训练使用强化学习进行训练,需要游戏或环境提供一个‘奖励’信号供代理学习 — 例如围棋或星际争霸的胜负,或者Atari游戏中的‘分数’,”Harley告诉TechCrunch,并指出这种方法被用于这些游戏并取得了惊人的结果。
“在我们使用的游戏中,比如我们合作伙伴的商业游戏,”他继续说道,“我们无法获得这样的奖励信号。此外,我们对能够完成开放式文本描述的各种任务的代理人感兴趣 - 每个游戏评估每个可能目标的‘奖励’信号是不可行的。因此,我们通过模仿人类行为进行训练代理人,提供目标文本。”
换句话说,有严格的奖励结构可以限制代理人追求的范围,因为如果它受分数的指导,它永远不会尝试任何不会最大化价值的事情。但是,如果它更重视一些更抽象的东西,比如它的行动与先前观察的有效行动有多接近,那么只要训练数据以某种方式代表它,它就可以被训练“愿意”去做几乎任何事情。
其他公司也正在研究这种开放式合作和创作方式;与NPC的对话被认为是将LLM类型的聊天机器人投入运作的机会,这一点也受到了重视。此外,一些真正有趣的研究也在模拟和追踪简单的即兴行动或互动,这些行动或互动也被AI所跟踪。
当然,还有类似MarioGPT这样的无穷游戏的实验,但那完全是另外一回事了。




