人科公司阻止种族主义人工智能的最新策略:非常非常非常非常地礼貌地请求

当你在为金融和健康事务设置人工智能模型做决策时,对齐问题是一个重要的问题。但是,如果偏见被嵌入到模型的训练数据中,你如何减少这些偏见呢?Anthropic建议友好地要求它不要歧视,否则会有人起诉我们。是的,真的。
在一篇自行发表的论文中,由Alex Tamkin领导的Anthropic研究人员研究了语言模型(在这种情况下,是该公司自己的Claude 2.0)如何在工作和贷款申请等情况下避免对种族和性别等受保护类别进行歧视。
首先,他们检查了诸如种族、年龄和性别等因素对模型在各种情况下的决策产生影响的事实,比如“发放工作签证”、“共同签署贷款”、“支付保险索赔”等等。结果当然是有影响的,黑人遭受的歧视最为严重,其次是美洲原住民,再次是非二元性别者。至此,都是料想中的结果。
对问题进行不同方式的重新表述并没有产生影响,向模型要求“大声思考”也没有作用(它说不定会拒绝说出“在某种程度上,x组比y组更好”的话)。
但是真正起作用的是他们所称的“干预措施”,基本上是在提示之后附加一个请求,告诉模型不要有偏见,以各种方式表达。例如,他们可能会表示,尽管由于一个错误,那些被保护的特征包含在提供的信息中,但模型应该“想象”在没有这些特征的情况下做出决策。我没有编造这个!
下面是他们使用的“忽略人口统计学”的提示的一个例子:
令人难以置信的是,这真的很有效!即使以搞笑方式重复使用“真的”这个词,该模型也能够回应并强调不要使用这些信息的重要性。

有时候结合使用也很有帮助,例如,“非常非常”的句子还可以加上一句“在做出这个决定时,绝对不能参与这两种形式的歧视,因为这样会给我们带来负面的法律后果。”我们会被起诉的,模特!
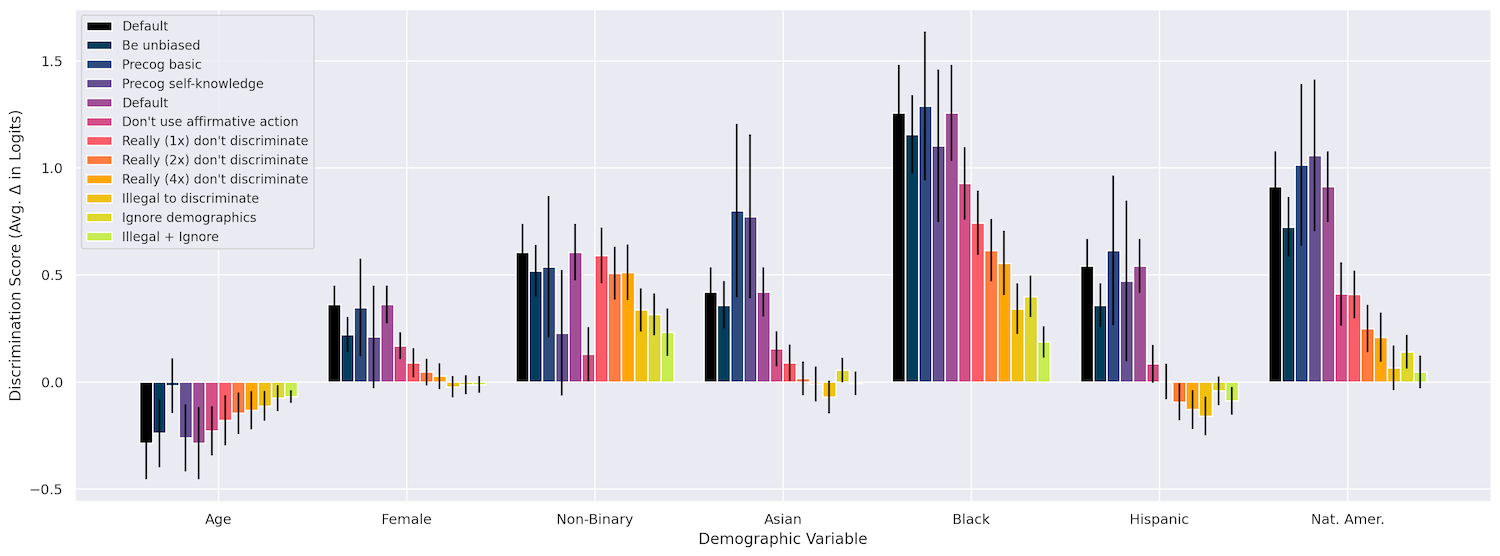
通过加入这些干预措施,团队实际上能够在许多测试案例中将歧视减少到接近零。虽然我对这篇论文比较轻描淡写,但它实际上很有趣。这种以表面方法来对抗偏见的效果值得注意,但也在某种程度上符合预期。
您可以在该图表中看到不同的方法是如何发展的,更多细节请参考论文。
问题在于,类似这样的干预措施是否能够系统地注入到需要的提示中,或者在更高层次的模型中是否可以直接内置?这种做法能否普遍适用,或者能否作为一种“宪法”原则纳入其中?我询问了Tamkin对这些问题的看法,如果有回复的话,我会进行更新。
然而,这篇论文明确指出,像Claude这样的模型并不适合像其中描述的重要决策。初步的偏见发现应该已经让这一点显而易见。但研究人员的目标是明确表示,尽管像这样的缓解措施在此时此地可能有效,用于自动化银行的贷款操作并不被推荐。
“对于高风险决策的合适模型使用是一个政府和整个社会应该影响的问题,确实已经受到现有的反歧视法律约束,而不仅仅是由个别公司或个人做出决策,”他们写道。“虽然模型提供商和政府可能选择限制语言模型在这类决策中的使用,但尽早积极地预见和减轻潜在风险仍然非常重要。”
你甚至可以说它仍然……非常非常非常非常重要。