OpenAI认为超级人工智能即将来临,并希望构建工具来控制它
当投资者为Sam Altman被OpenAI无礼撤职而准备引发争议时,Altman则在策划着重返公司的计划。与此同时,OpenAI的超级对齐团队成员们一直努力解决如何控制比人类更聪明的人工智能的问题。
或者至少,那是他们希望给人的印象。
本周,我与Superalignment团队的三位成员进行了一次电话会议——Collin Burns、Pavel Izmailov和Leopold Aschenbrenner——他们正在新奥尔良参加年度机器学习会议NeurIPS,介绍OpenAI关于确保人工智能系统按预期行为的最新工作。
OpenAI于七月组建了超整合团队,旨在开发能够引导、调节和治理“超智能”人工智能系统——也就是理论上智能远超人类的系统。
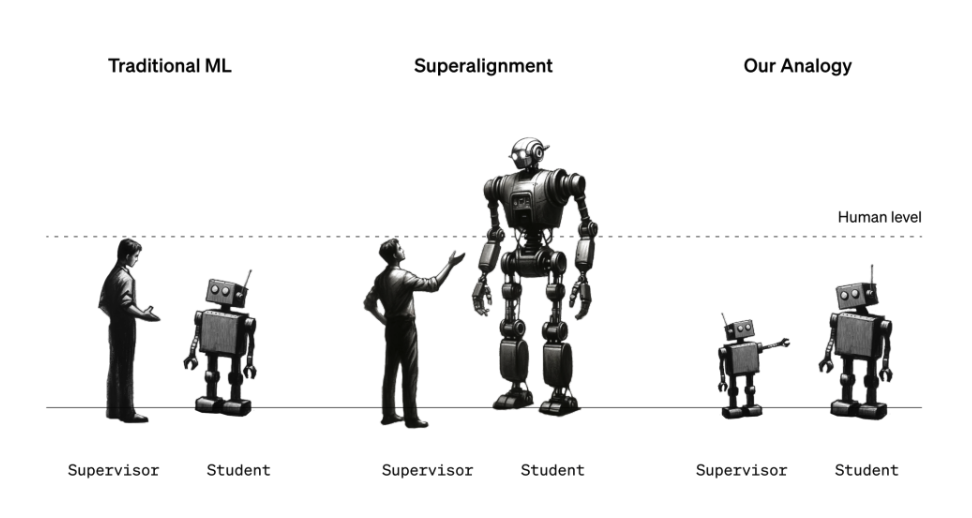
“今天,我们可以基本上与比我们更笨的模型对齐,或者最多与人类水平相当的模型对齐,”伯恩斯说。“让一个比我们聪明的模型对齐则要明显困难得多 - 我们究竟能如何做到呢?”
超级对准(Superalignment)计划目前由OpenAI的共同创始人和首席科学家Ilya Sutskever领导。在七月份时,这并没有引起人们的注意,但现在的情况是,Sutskever曾是最初主张解雇Altman的人之一,因此他的领导地位引起了关注。尽管有报道称Sutskever在Altman回归后处于“悬而未决”的状态,OpenAI的公关告诉我,至少目前来看,Sutskever仍然是超级对准团队的负责人。
超对齐在人工智能研究界是一个比较敏感的话题。有些人认为这个子领域还不够成熟,而其他人则暗示它是一个红鱼(注:中国大陆俚语,意为误导或分散注意力的东西)。
尽管Altman已经在邀请人们将OpenAI与曼哈顿计划进行比较,甚至组建了一支团队来研究AI模型以防止“灾难性风险”,包括化学和核威胁,但一些专家表示,目前或者永远没有证据表明这家初创公司的技术能够具备毁灭世界、超越人类的能力。这些专家还指出,关于即将到来的超级智能的声明,只是为了故意将人们的注意力从当今AI监管问题、如算法偏见和AI对毒性的倾向,转移开来。
无论如何,Sutskever似乎真诚地相信人工智能(AI)将来可能构成一种存在威胁,不是OpenAI本身,而是它的某种体现。据报道,他甚至组织了一次公司外活动,点燃了一个木偶,在示范其致力于防止人工智能对人类造成伤害的同时,他还管理了OpenAI中一定数量的计算资源——占据了其现有计算芯片的20%,用于超级对齐团队的研究。
阿什恩布雷纳说:“最近人工智能的进展非常迅速,我可以向你保证它不会放慢脚步。我认为我们很快就会达到人类水平的系统,但不会止步于此 - 我们将不断发展到超人类的系统......那么我们如何使超人类的人工智能系统保持安全呢?这实际上是一个关乎全人类的问题 - 或许是我们这个时代最重要的未解决的技术问题。”
目前,超级对齐团队正在尝试构建适用于未来强大人工智能系统的治理和控制框架。考虑到“超级智能”的定义以及某个特定的人工智能系统是否达到该标准仍存在激烈的争议,这并不是一个简单的任务。但目前团队采用的方法包括使用一个较弱、较不复杂的人工智能模型(如GPT-2)来引导一个更先进、更复杂的模型(GPT-4)朝着期望的方向发展,避免朝着不期望的方向发展。
“我们努力做的很多事情是告诉模型应该怎么做,并确保它会按照我们的指示去做,”伯恩斯说道。“我们如何让模型遵循指令,并且只帮助正确的事情,而不是胡编乱造?我们如何让模型告诉我们它所生成的代码是否安全或是否存在不当行为?这些都是我们希望通过我们的研究能够实现的任务类型。”
等一下,你可能会说 - 人工智能引导人工智能与防止威胁人类的人工智能有什么关系?嗯,这是一个类比:弱模型用来代表人类监督员,而强模型代表着超级智能人工智能。类似于人类可能无法理解超级智能人工智能系统,弱模型无法“理解”强模型的所有复杂性和细微差别 - 这种设置对于验证超对齐假设非常有用,超对齐团队说道。
“你可以把一位六年级学生试图监督一位大学生理解为,”伊兹迈洛夫解释道,“假设六年级学生试图告诉大学生一个他有点知道如何解决的任务...尽管六年级学生的监督在细节上可能会出错,但还是有希望大学生能够理解主旨,并且能够比监督者更好地完成任务。”
在超级对齐团队的设置中,一个在特定任务上进行微调的弱模型生成标签,这些标签被用来“传达”该任务的大致情况给强模型。据团队发现,有了这些标签,强模型可以根据弱模型的意图进行更或少正确的泛化,即使弱模型的标签包含错误和偏见。
团队表示,弱强模型方法甚至可能在幻觉领域取得突破。
阿什恩布伦纳说:“幻觉实际上很有趣,因为在内部,这个模型实际上知道它所说的是事实还是虚构。”他说:“但是目前这些模型的训练方法是,人类监督者通过给它们‘赞’或‘踩’来奖励它们说话。所以有时候,无意中,人类会奖励模型说一些虚假的或者模型实际上不知道的事情。如果我们的研究取得成功,我们应该开发一种技术,可以从模型的知识中提取并对某件事情是事实还是虚构进行判断,并利用这个方法减少幻觉的发生。”
但这个类比并不完美。因此,OpenAI希望通过众包的方式收集想法。
为此,OpenAI将推出一项1000万美元的资助计划,用于支持关于超级智能对齐的技术研究。其中一部分将保留给学术实验室、非营利组织、个人研究人员和研究生。OpenAI还计划在2025年初举办一次关于超级智能对齐的学术会议,届时将分享并推广超级智能对齐奖的入围作品。
有趣的是,这项资助的一部分资金将来自前谷歌首席执行官兼董事长埃里克·施密特。施密特是阿尔特曼的忠实支持者,他正在成为人工智能悲观主义的代言人,坚称危险的人工智能系统即将到来,监管部门在准备方面做得不够。这并不完全是出于利他主义的考虑——《Protocol》和《Wired》的报道指出,作为一位活跃的人工智能投资者,如果美国政府实施他提出的加强人工智能研究的蓝图,施密特在商业上将获得巨大的利益。
捐赠行为可能会被以一种愤世嫉俗的眼光视为虚伪的美德展示。施密特个人财富约为240亿美元左右,并且他还向其他明显不以伦理为重点的人工智能企业和基金注入了数亿美元,其中包括他自己的企业。
施密特当然否认了这一点。
他在一封电子邮件声明中表示:“人工智能和其他新兴技术正在重塑我们的经济和社会。确保它们与人类价值观相一致至关重要,我很自豪支持OpenAI的新[资助],以负责任地发展和控制人工智能,造福公众。”
事实上,涉及这样一个透明商业动机的人物,必然引发一个问题:OpenAI的超级对准研究以及它鼓励社区提交给未来会议的研究,是否会被开放给任何人按照他们的意愿使用?
超对准团队向我保证,是的,OpenAI的研究,包括代码,以及那些从OpenAI获得超对准相关工作的资助和奖励的他人的工作,将会公开分享。我们将会跟踪该公司以确保其兑现承诺。
"贡献不仅仅是为了我们模型的安全,也是为了其他实验室的模型和普遍的先进人工智能的安全是我们使命的一部分," Aschenbrenner说道。"这是我们为了造福全人类而构建人工智能的使命的核心所在,安全性同样重要。我们认为进行这项研究对于使其具有益处和安全性是非常必要的。"




